Haxe 4.1.0 release
Reading and watching the news over the last two months has not been very pleasant. Everything gets canceled, and what doesn't get canceled gets delayed. To be fair, the release of Haxe 4.1.0 is a bit delayed as well. But, as it is known, all's well that ends well and we did our best to make this Haxe release cycle end well! So here is the Haxe 4.1.0 release with some new features, plenty of improvements, lots of bugfixes, and no viruses.
Check it out now at https://haxe.org/download/version/4.1.0/.
In this post we would like to give an overview of some of the changes. To be perfectly honest, the changelog this time around isn't very flashy. However, this is normal for the first minor release after a major one, where some dust has yet to settle and kinks have to be ironed out. Still, some changes are quite nice and lay the groundwork for future improvements that are even nicer. So let's get started!
JVM is now the fastest Haxe target
Ah, I clearly want my "Is NodeJS wrong?" moment with a heading like that! However, there is actually some data to back up this claim. This is thanks to the efforts of Alexander Blum aka AlexHaxe aka "the Haxe formatter guy", who took charge of implementing https://benchs.haxe.org/. Hugh Sanderson once told me that optimization is fun because you get a score. I couldn't agree more!
If you check these benchmark graphs, you will find that the JVM target does well in all of them. Though not necessarily the fastest in every single one, its overall performance suggests that it is capable of handling a wide variety of Haxe applications. For example, here's a current comparison of our fastest targets for the Haxe Formatter Benchmark:
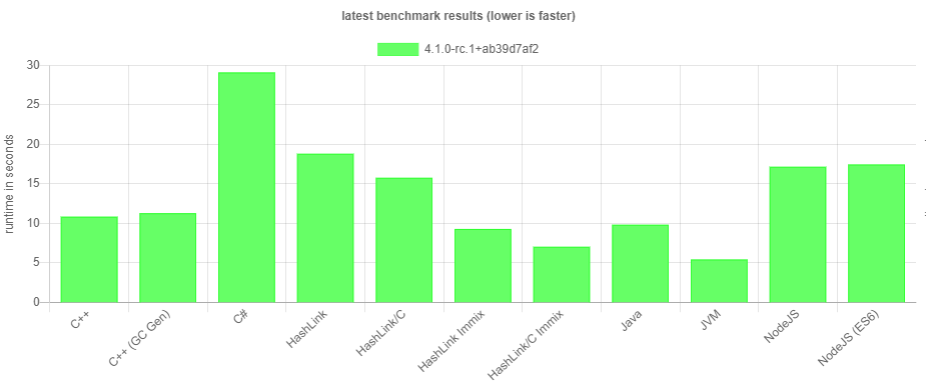
Of course this wasn't always the case. In fact, I was so disappointed with the JVM target's performance originally that I proposed removing it before the Haxe 4.0 release. In hindsight, I'm grateful that Dan, Jens and the others convinced me to stick with the target and helped me to improve it by testing, profiling and designing how to handle stuff.
Speaking of which, one of the major improvements we've made since Haxe 4.0 is the representation of anonymous functions and closures. This used to be implemented using java.lang.invoke.MethodHandle and has now been replaced by a different approach. Just look at this benchmark drop after implementing it:
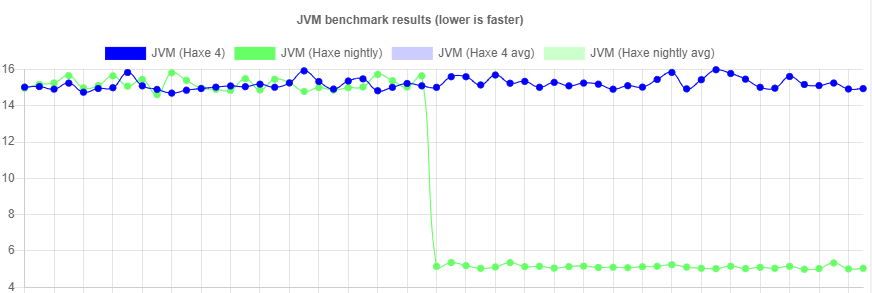
I might go into detail about how these functions actually work in a separate post. For now, the message I want to convey is that the JVM target is here to stay and contend with the other Haxe targets as far as performance is concerned (especially if you also take compilation time into account). There are still some problems to solve, most notably how to handle debugging. If anyone has Java-specific knowledge of that, please let us know!
Finally, I would like to thank EJ Technologies for providing us with a free open source license for JProfiler. This proved to be an amazing tool for identifying and analyzing performance bottlenecks.
haxe.Exception
Up until now there wasn't a lot of design around exceptions in the Haxe world. The gist of it was that you can throw and catch any value, and if you wanted to inspect stack traces you would use the haxe.CallStack API. First of all, the aforementioned still works as before. However, we have introduced a new class haxe.Exception to unify exception handling across targets.
Here's some general guidelines for how we envision this API being used:
Catching haxe.Exception
Instead of catching Dynamic, you can now catch haxe.Exception:
Before:
try { } catch(e:Dynamic) { }
Now:
try { } catch(e:haxe.Exception) { }
Note that it is also possible to write catch (e). In this case, the compiler will infer the type of e to haxe.Exception.
Call stacks
All exceptions have a stack field which holds the exceptions's stack trace:
Before:
} catch (e:Dynamic) { trace(haxe.CallStack.exceptionStack()); }
Now:
} catch (e:haxe.Exception) { trace(e.stack); }
Custom exception classes
Custom exception classes can just extend haxe.Exception:
class FooException extends haxe.Exception {} class Main { static function main() { try { throw new FooException("foo"); } catch (e:FooException) { trace(e); } } }
Transition
We encourage using this API for new code which doesn't need to support Haxe versions before 4.1. It is not necessary to adapt code to this: The compiler and code generators ensure that arbitary values are properly wrapped into and unwrapped from instances of haxe.Exception in a way that doesn't surface to the user. You are free to keep throwing such values; just note that there might be a bit more going on in the background now.
The Haxe interpreter now supports SSL
It is now possible to make https requests directly in the interpreter:
class Main { static function main() { trace(haxe.Http.requestUrl("https://haxe.org")); } }
It's not hard to imagine the standard reaction to this being something along the lines of "Oh that didn't work before?" as https requests are not exactly a rarity nowadays. Nevertheless, implementing this in the interpreter was not quite trivial. We achieved this by binding mbedTLS which came with two challenges:
-
We needed bindings to the mbedTLS C API which appease the OCaml GC. Writing these is about as much fun as doing your taxes, and it's just as easy to make mistakes. These mistakes typically manifest as hard crashes that leave you wondering what's wrong, and sometimes even adding a debug print ends up "fixing" such a crash because it causes garbage collection behavior to change.
-
Linking mbedTLS had to be dealt with. This is not so difficult on real operating systems, but turned out to be quite the hassle on Windows. In the end, I made a pseudo cygwin package for this which for now has to be manually extracted. The plan is ultimately to have this as an official cygwin package that can be installed normally, so if anyone has aspirations to become a cygwin package maintainer, please get in touch!
Tail Recursion Elimination (TRE)
It might be surprising to hear that, at low-level, function calls are actually somewhat expensive. In the general case, executing a function requires some sort of frame which holds data for local variables and also probably some debug information. Calls may also require dealing with CPU registers to make sure no live data in those is overwritten by the callee. As a result, it is desirable to avoid function calls where possible.
In computer science class we learn that any recursion can be expressed by an equivalent loop. However, one version might look much nicer than the other. This can lead to a dichotomy where an recursive algorithm looks better, but performs worse than its looping equivalent. Fortunately, compilers can, in some instances, resolve this problem by rewriting recursion to a loop. This gives us the best of both worlds: Good looking code with good performance.
As an example, here is some code from the implementation of haxe.ds.BalancedTree:
static function iteratorLoop<K, V>(node:TreeNode<K, V>, acc:Array<V>) { if (node != null) { iteratorLoop(node.left, acc); acc.push(node.value); iteratorLoop(node.right, acc); } }
BalancedTree is a port of the OCaml implementation of pMap. Since OCaml has strong support for the functional programming paradigm, this recursive implementation is very natural there. When the Haxe port was written, the author paid no mind to the fact that this wasn't the case for Haxe (what an idiot). Thankfully, this has now improved with the arrival of tail recursion elimination, which we can see in action in this diff:

At a first glance, it might be unexpected that something with "elimination" in its name causes more code to be generated. However, this is a natural consequence of what we just established: The recursive version certainly might look nicer, but what we're ultimately interested in when it comes to generated code is performance.
Note that only the second call to iteratorLoop has been rewritten. This is why the feature is named tail recursion: We obviously cannot just loop on the first call because control flow is supposed to continue with the acc.push line afterwards. This kind of optimization only works if nothing else happens after the recursive call, which is something to keep in mind.
In summary, you can now use recursion more freely in Haxe and don't have to worry about manually making awkward rewrites to a loop. This can lead to code that is easier to read and maintain, while still performing well.
What's next?
There are several features that are planned for inclusion in future releases. In some instances, we aren't quite sure yet which exact release will come with which of these features. If you have any thoughts on any of these, feel free to let us know!
Module-level static declarations
The idea is to allow functions and variables to be declared directly in a module (i.e. a .hx file) without the need to wrap them in a class. See https://github.com/HaxeFoundation/haxe/pull/8460.
Asynchronous system API (asys)
We want to provide an asynchronous API for working with files, sockets and the like. See https://github.com/HaxeFoundation/haxe/pull/9111.
Improvements to haxelib
With the lix package manager gaining more and more traction, we would like to investigate what could be done to make its haxeshim component unnecessary. See https://github.com/HaxeFoundation/haxe/issues/9135.
Coroutines
Support for coroutines has been in the design phase for quite a while now. We are not quite sure yet what we want to do here and how we want to approach it, but by now several ideas are on the table and have been discussed.
Haxe-in-Haxe
A long-term goal is still to implement Haxe in Haxe instead of OCaml. There are several challenges and questions here which have to be addressed. See https://github.com/HaxeFoundation/haxe/issues/6843
Thank you
With that, we would like to thank you for your continued support. None of this would be possible without the Haxe Foundation partners. Furthermore, I would like to thank everyone who volunteers their time and skills in pursuit of Haxian greatness.
Finally, a quick note on the Haxe Summit 2020: We've been silent about this for obvious reasons, and at the current point in time we still can't tell what is going to happen. October is still several months away and there's a chance that all the current worries will be a thing of the past by then. We are likely not going to make a call before some time in July.
Until then, stay healthy and enjoy the Haxe 4.1.0 release!
