About two weeks ago, I finished my Master's thesis with the topic "Modern Garbage Collector for HashLink". The primary goal was to improve HashLink performance in memory-intensive applications. You can watch the video of my thesis presentation here. In this post I will try to summarise some parts of my project and how it can improve your experience with HashLink.
The performance problem
First of all, why bother? Haxe's C++ and JVM target already perform very well. Why base a project on improving the performance of another target?
For one, it's a very interesting engineering problem! A large part of my thesis was actually about creating a model and formally verifying the garbage collector, but I will not go into detail about that in this post. If you are interested, you can have a look at the video linked above.
But personal interest aside, HashLink has the potential for great performance. This is especially visible with the HL/C target, which can be optimised by powerful compilers such as GCC or Clang. We can see this on the N-body benchmark:
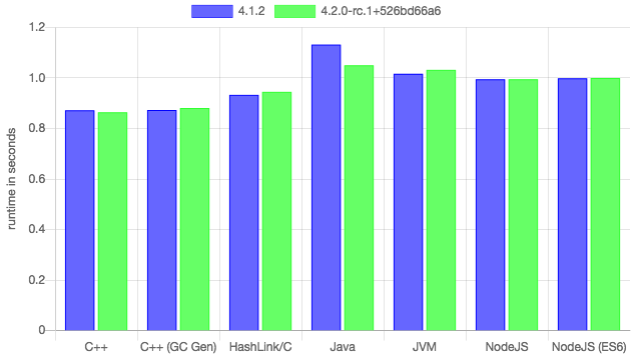
HL/C actually beats all Haxe targets in this benchmark except for C++. However, the compilation time is much faster for HL/C, and much faster still for HL/JIT, which is very useful for debug builds. On the other hand, HashLink performs measurably worse when memory allocation is involved. We can see this on the Mandelbrot benchmark, which performs thousands and thousands of object allocations:
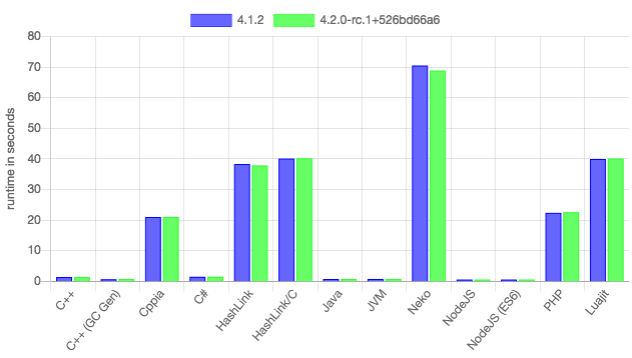
In this benchmark, HashLink is far behind C++ or Java. If memory was managed better in HashLink, it would be a target with great runtime performance, great compile times, and a lot of control, since it was written for Haxe to begin with.
Old approach
HashLink's old approach is "mark-and-not-sweep", according to Nicolas. It is a variant of the classic mark and sweep algorithm. The "not sweep" part means objects are not really swept in a separate phase but rather spaces for new objects are found when allocating. This reduces GC pause time, but results in slow allocation.
Besides being harder to implement, there are some reasons why HashLink cannot use a moving or copying GC without modifying a lot of its supporting libraries. The main reason is the HL/C target, which produces C code that goes through a regular C compiler. This results in heavily optimised binaries, but also less control over how pointers and objects are treated.
To avoid a complex API, the HashLink GC simply provides an allocation operation, then tries to figure out which objects are reachable from each thread by scanning the registers and the stack. This is the standard approach for conservative collectors (such as Boehm GC), but it comes with some problems. Values in the stack or registers at any point during the execution of the program may essentially mean anything. If a value looks like a pointer and there is an object allocated by the GC at the given address, then the GC must assume that object is live. However, the value might have been a big integer or float that just happened to look like a pointer. In this case we simply keep unnecessary objects around, resulting in a slightly higher memory usage.
The opposite case is the worse problem—sometimes, there are live, reachable objects that the program is using, but they are not obviously identifiable from the registers or the stack. It may be because the pointer is "masked" (e.g. combined with another pointer using XOR), or that the pointer is actually an interior pointer, pointing to the middle of an object rather than its beginning. Although these issues are relatively rare, they can cause serious problems. If an object is treated as unreachable, and its memory is freed or given to another object, the program may crash, find non-sensical data in its memory, or behave in a type-unsafe manner.
Allowing objects to be moved by the GC would make these problems much worse still, because it would require overriding pointers identified in the stacks and the registers, or at least pinning such objects (a "pinned" object is never moved). So, at least for now, HashLink is constrained to a non-moving, non-copying collector.
New approach
For my project I chose to write a GC based on Immix. This may sound familiar to you, since a modified Immix is also used in Haxe's C++ target. It makes sense as a choice, since it has proven itself in practice, and because it can be easily made into a non-moving collector, to work within HashLink's constraints.
Immix divides the memory into small, 64-KiB "blocks", and those blocks are then divided into 128-byte "lines". Blocks are "owned" by threads, so the most common case for object allocation does not require thread synchronisation. Allocation is also performed using an extremely fast method called "bump allocation" (or "linear allocation"). This means we only keep a pointer to the beginning of some free memory, and a limit that we shouldn't cross when allocating. If there is enough space for allocating the needed object, we simply move the pointer up by that amount (it is "bumped"), and allocate the object in the old position. With this approach, allocation is very fast for the majority of objects.
Sweeping is done at a coarser level than typical mark-and-sweep. Instead of freeing any object that is unreachable and adding it to the free memory, Immix only sweeps based on the "lines", which are in general larger than the objects they contain. A line is only considered free when it contains no reachable objects. This leads to some memory being wasted, since a single small object can keep an entire line alive, but, somewhat counter-intuitively, it is better suited for modern CPU architectures and memory caching.
Results
So how fast is it? Here is a plot comparing the new GC to the old one on various Haxe benchmarks:
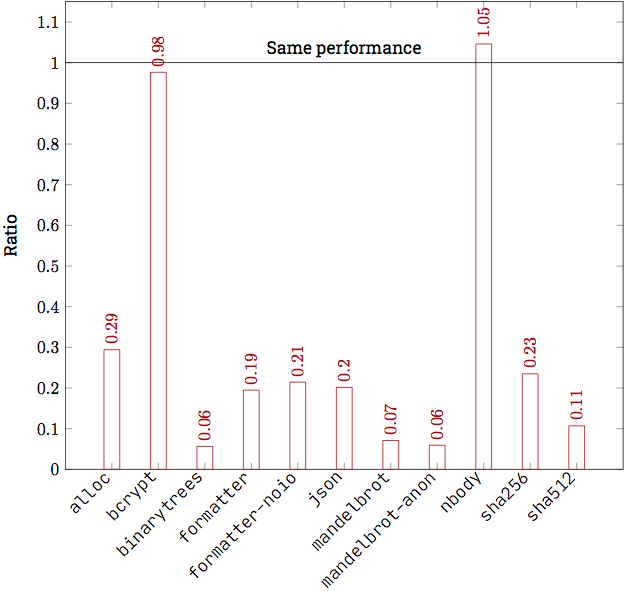
As you can see, the ratio depends a lot on the specific benchmark. The N-body benchmark, for example, does almost no memory allocation, and so it performs about the same with both GCs. On the other hand, the Mandelbrot benchmark is about 14 times faster!
Of course, both N-body and Mandelbrot are very small applications ("microbenchmarks") that may not reflect realistic usecases of HashLink. For this, the Formatter benchmark is the most useful, since it has a large codebase, performs many operations and uses the memory in various allocation patterns. On this benchmark, the new GC is about 5 times faster.
You can see the benchmark results of the new GC on the benchmarks page, where the new implementation is called "HashLink Immix". Note that some benchmarks show no result for the new implementation, because they still crash at runtime!
Future
The most obvious next step is to finish the PR implementing the new GC. Some bugs still need to be fixed, and the codebase needs to be "re-aligned" to the existing HashLink codebase, so that the two collectors can be tested in parallel, by simply compiling HashLink with a different compile-time switch.
Later, once the GC is working as intended and proves to be better for performance in general, we may want to consider more ambitious optimisations, and more complex collection schemes. A generational approach (as used in the C++ target) in particular may be very useful, although this might require losing the "no moving" constraint.